据说,OceanBase的CTO杨传辉曾经说过:“构建一个分布式数据库存储系统是比较简单的,上层一套raft一致性协议,下层接一个RocksDB引擎,一周时间就能搞定,难得是如何保证系统在后续的运行中性能稳定且可靠”。且不论一周时间到底够不够,不可否认的是,Raft协议的出现使得构建一个分布式系统简单了许多。
但即使Raft作者把各种工程问题解决之道都写在了他的博士论文里,真正去实现一个高效稳定的Raft库仍然要费很多心思。此外,库的使用者也必然会遇到各种意想不到的问题。
由于工作的关系,笔者深度使用了braft一段时间。总体来说braft是一个完成度很高的工业级实现,省去了团队不少开发及测试的时间。但是当然也遇到了不少坑。因此本文将分享一些笔者在使用/魔改braft的一些小经验,希望能让你少踩点坑。
如下图所示,使用Raft的系统可以分为两大部分:Raft算法和状态机。简单来说,Raft算法约定了如何选出leader、日志如何进行复制、日志什么时候被认为committed,通过这些约定保证了日志的一致性;而状态机则是在得知日志commit后按照日志内容修改自身状态(即日志apply到状态机)。
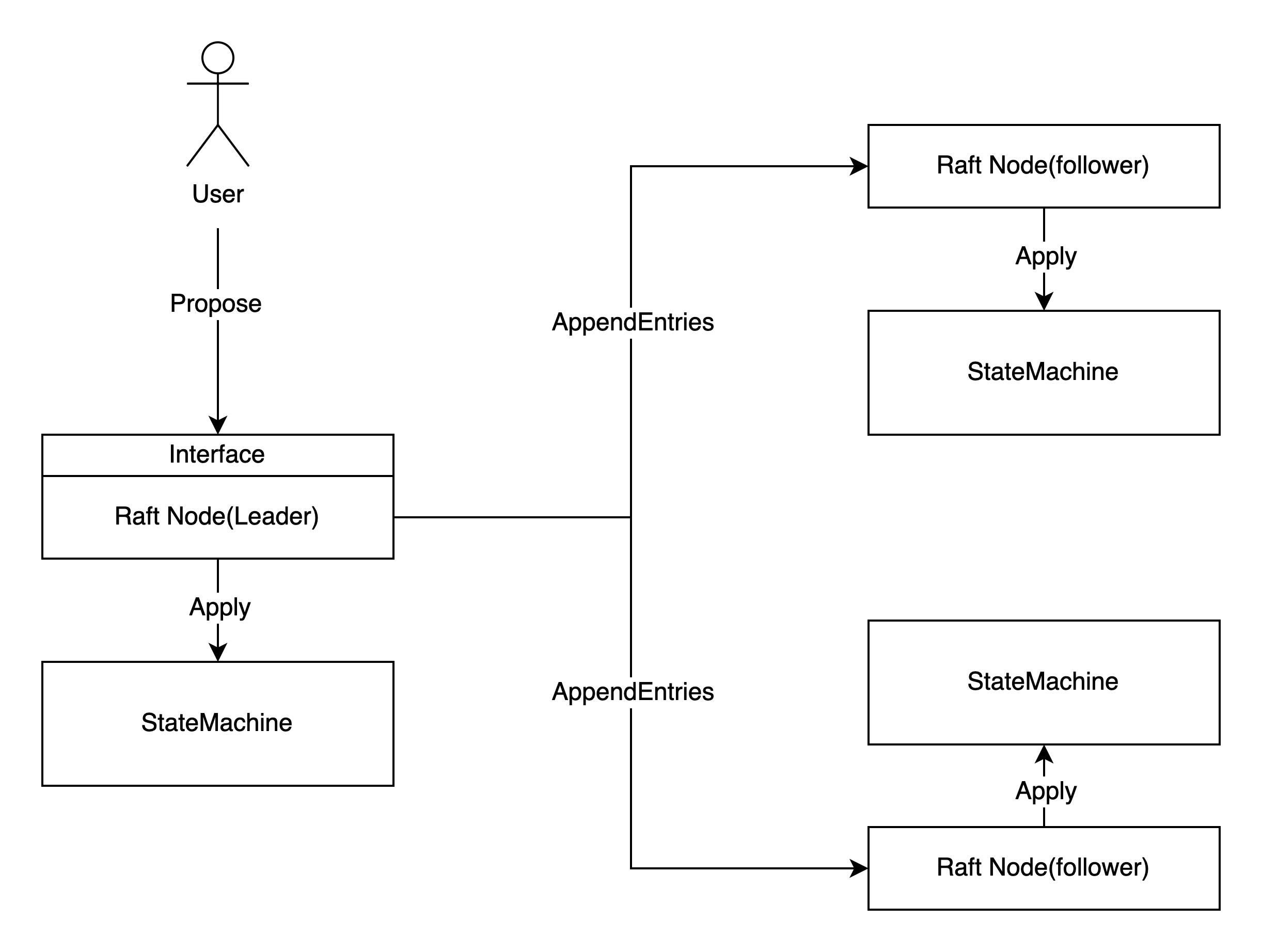
绝大多数的Raft库都是异步的,即日志的复制与日志的apply互相不阻塞。因此,使用Raft的过程中要时刻意识到状态机的状态有可能“不够新”。例如某条日志实际上已经达成一致很久了,状态机却还没有进行相应的更新,这可能是因为:1. 它还未得知这条日志达成一致这个信息;2. 或是负责更新状态机的线程还未处理到这条日志。
基本使用姿势
作为Raft论文的忠实实现,braft自然也为用户提供了日志与状态机两个结构。
- Raft节点
braft::Node。用户需要构造出braft::Node,用以提交日志,即调用void apply(const Task& task)接口(个人认为应该把apply改名为propose)。 - 状态机。用户需要继承
braft::StateMachine,实现状态机的各个接口以完成自己的业务逻辑,其中on_apply是必须实现的。如果一切顺利,braft会串行地调用状态机的on_apply接口,先前通过apply接口提交的日志就能从on_apply中取出。
有了这两个接口,就已经能实现一个简单的分布式服务了:
1 | // https://github.com/baidu/braft/blob/master/example/atomic/server.cpp |
读请求优化
很显然,只读请求也需要经历一轮raft协议是非常低效的做法。对于只读请求来说,要想实现线性一致性并不需要这种完全串行化的做法。
Raft作者给出了两个方案(见博士论文第6.4节 Processing read-only queries more efficiently):Read Index与Lease Read。它们的核心思想都是只要能确认自己是leader && 自己的状态机足够新,就可以直接读取状态机里的值而无需通过Raft Log。
那么如何在braft中实现呢?
braft目前还不提供Read Index,故不予考虑该方案
尝试1. 利用on_leader_start来实现
稍加浏览,不难发现braft::StateMachine提供了leader相关的接口可供覆写:
virtual void on_leader_start(int64_t term);virtual void on_leader_stop(const butil::Status& status);
那么自然我们想到一个做法:on_leader_start时标记自己是leader,可以直接处理读请求;on_leader_stop时标记自己是follower,不再处理任何请求。
braft官方给出的example也是这么写的:
1 | // https://github.com/baidu/braft/blob/master/example/counter/server.cpp |
然而,眼尖的读者可能已经发现,这样写有可能导致stale read。
虽然on_xxx系列接口之间是串行的,但get接口与它们却是完全并行的。
假设节点A在t0时刻on_leader_start,t1时刻变为follower,t2时刻才on_leader_stop。那么在t1~t2期间get请求全都能成功,实际上不应该成功。
更糟糕的是t1~t2这个时间窗口可能任意长(比如on_leader_stop卡住了)。
尝试2. 利用leader lease实现lease read
既然问题出在on_leader_stop的调用没那么及时,那我校验leader lease来保证自己是leader总没问题了吧。于是加了个条件,代码变成这样:
1 | bool is_leader() const { |
很可惜,这样的写法仍然是错误的。假设节点A在t0时刻on_leader_start(term=1)了,t1时刻变为follower,t2时刻B选为term=2的leader,t3时刻A又选为term=3的leader,t4时刻A才on_leader_stop(term=1)。那么t3~t4内is_leader_lease_valid返回true(term=3的lease),且_leader_term == 1 > 0,两个条件均满足,于是get请求全都能成功,实际上不应该成功。
正解. 校验leader lease的term与状态机的term是否一致
事实上,前面两个方案都不满足“状态机足够新”这个前提。
想要实现这个约束,只需要检查leader lease的term与状态机的term是否一致。这是因为在braft中,刚选为leader时就会propose一条no-op日志,当apply到这条日志时,意味着此前所有term的数据都应用到状态机了。如果此时leader lease有效,意味着没有别的leader,新的写入都在自己身上,因此自己的数据一定是最新的。
1 | bool is_leader() const { |
tikv也有类似的逻辑。
1 | // https://github.com/tikv/tikv/blob/v5.3.0/components/raftstore/src/store/worker/read.rs#L260-L277 |
也许你会问,为什么只需要校验状态机当前的term是否足够新,而不需要校验状态机当前的index是否足够新呢?
答案很简单,服务端是在apply完成后才向用户返回成功的,而不是日志commit时就返回成功。因此还未apply的日志还不算写入成功,那么读不到也是应该的。
也许你还会问,如果校验leader lease成功后线程卡住了,过了很久才读取数据,不还是会读到stale data吗?
比如这样:
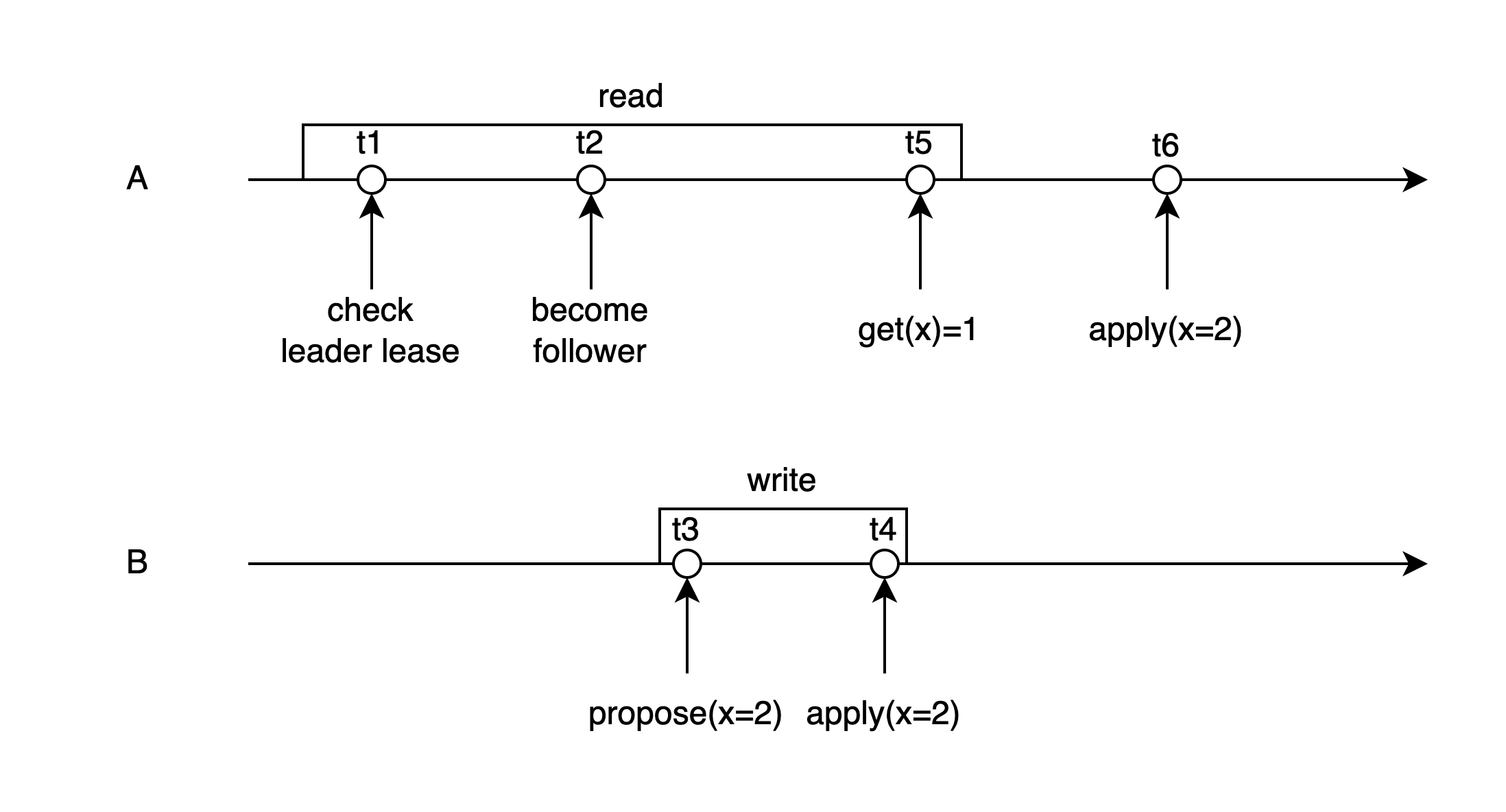
假设初始时x=1,节点A在t1时刻校验leader lease成功,t2时刻lease失效,随后节点B当选leader,并且在t3时刻propose了一个新值x=2,t4时刻apply成功,t5时刻A读取数据。由于t6时刻A才apply x=2,这次读请求会返回旧值x=1。
是的,是会读到旧值,但不违反线性一致性,因为这两个请求并发了。对于并发的读写请求,返回新值还是旧值都是合理的。线性一致性要求的是t4时刻之后,所有新的读请求都必须读到x=2而不是x=1。如果再考虑到不少系统采用的是快照读,这个读请求更是只能返回x=1,当然这就不属于Raft的范畴了。
事实上,由于从发送请求到结果返回是需要时间的,读到stale data是不可避免的。即使采用“基本使用姿势”中完全串行化的做法,也会受到网络的影响,导致读请求的结果很晚才到达客户端。
踩坑. follower也会遇到iter.done() != NULL
braft的接口是异步的,在调用void apply(const Task& task)时,用户可以往task.done里塞入一个Closure回调对象。如果未达成一致,则braft会单独启动一个协程(bthread)调用done->Run()用以通知调用方。
如果达成一致,则braft只会调用on_apply,通过Iterator让用户迭代每条日志,而不会调用done->Run(),注释是这么说的:
1 | class Iterator { |
翻译一下,done()如果非空,则用户必须自己调用done()->Run();而done()当且仅当 1. 这个task是这个Node还是leader的时候propose的;2. 直到此时leader还没变过 这两个条件都满足时非空。并且它的值就是此前用户往task.done里塞的值。
那很自然,我们会认为on_leader_stop之后的所有iter.done()都是空的。因为此时leader已经stop了,不满足条件2。
然而现实并非如此。对于transfer leader场景,braft会让leader的状态机执行on_leader_stop,如果此时follower发来了AppendEntries成功的回复,则commitIndex将推进,braft又会让leader状态机执行on_apply。于是预期外的状态出现了:明明已经on_leader_stop了,却还有iter.done() != NULL。严格来说这也不算注释有bug,因为此时leader还没有changed。
如果你的Run()函数处理逻辑依赖于on_leader_start/on_leader_stop,那你要小心检查是否能正确处理这个情况。
未决日志的处理
任何分布式系统的请求与响应都有三态:成功、失败、超时(未知)。Raft也不例外,未在用户指定时间内达成一致/apply即属于超时。此时要么选择重试(需要保证幂等);要么选择死等,等到确定了成功/失败后再进行下一步操作。
除了这种常见的超时导致的未知,还有一种特殊场景的未知。即用户propose了一条日志,当leader(A)已经将该日志在本地落盘,却还未commit时发生了leader切换,此时结果未知:1. 新leader还是A自己,则该日志随着A新写的no-op日志的commit而commit; 2. 该日志还没发给别的follower,新leader不是A自己,则该日志随着新leader的no-op日志commit之后而盖棺定论:它不可能达成一致了;3. 该日志发给了某个follower,新leader是这个follower,则该日志会随着no-op日志的commit而commit。
对于这种场景,braft的处理是直接报错,即单独启动一个协程(bthread)调用done->Run()用以通知调用方结果未知。这时可以选择让客户端直接重试(同样,需要保证幂等),也可以选择在服务端死等。等到什么时候呢?等到状态机收到新的no-op日志即可。如果达成一致,则状态机已经apply了用户提交的日志,向用户返回成功即可。
Multi-Raft 带来的随机写
对于一个分布式系统,能够在一定范围内水平扩展是基本需求。这意味着整个集群必然不能只有一个Raft Group。
此外,即使是一个只有3节点的系统,也需要多个Raft Group才能发挥出硬件的全部性能。
因为在Raft中只有leader才提供读写服务,也就是其余的两个follower相对空闲。那么只有一个Raft Group的话就意味着两台机器较闲。
因此,工程上基本都需要对数据进行分片,每个分片的多个副本组成一个Raft Group,整个系统有多个Raft Group(即Multi-Raft),从而达到均衡负载的目的。
然而,braft的存储层是per-Node的,每个braft::Node持有一个目录,顺序追加自己的日志。当单台机器上的Raft Group数量较多时,对于IO设备来说就相当于随机写。在我们的机器上实测当组数大于8时,就能观察到明显的吞吐下降。为了解决这个问题,一些其他Raft库直接采用了现成的存储引擎。比如braft的Java移植版sofa-jraft就使用RocksDB;TiKV也是使用RocksDB;dragonboat则采用了CockroachDB的pebble。
而我们的做法则是重写了存储层,不同的Raft Group共用Raft Log,采用单线程组提交的方式实现顺序写。除了避免随机写,和RocksDB比这样做还减少了磁盘IO,这是因为Raft Log需要经常的删除前缀,RocksDB在这种情况下会带来额外的写放大。缺点是Log文件的删除变得相对复杂。比如一个日志文件里大部分的日志都由于做了snapshot而不再需要了,却有某个Group还有少量日志,则这个日志文件仍需要保留,浪费磁盘空间。因此我们也相应开发了log compact的功能。
缓存未apply的日志
出于性能考虑,braft对于已经commit但还未apply的日志的处理是全部缓存在内存中,预期是这些日志很快就要输入给状态机。这样的做法能够大大减少读盘次数。
然而,这样的缓存策略有bad case。考虑某个follower宕机重启的场景,一方面它需要重新apply一遍宕机前已有的日志,另一方面leader还在不停地给它发送新的日志。如果按照前面所述的策略,此时所有新日志都会被缓存在内存。如果存量日志很多,则这个过程会很长,甚至有可能导致OOM。
解决方法也很直接,加个缓存容量限制即可。简单粗暴的话就设置一个常量n,每个raft node最多缓存n条日志。更精细一些的话可以设置一个进程级别的总限制n,考虑不同raft node的写入量,给写入量大的raft node分配较大的n_i。
全新的Raft Group尽快提供服务
启用了lease机制后,一个新实例化出来的braft::Node要先sleep选举超时时间+最大时钟漂移时间后才会发起选举。在进程宕机重启的场景下,这是必要的,否则有可能违背了对leader lease的承诺。但对于一个全新的Raft Group来说这是完全不必要的——此前必然没有作出过任何承诺。因此可以立刻发起选举,尽快对外提供服务。为此笔者也提了一个pr给braft官方。
结语
本文主要介绍了利用braft实现lease read的方式,此外还分享了一些遇到的坑/可以采取的优化。希望对你有帮助: )。