论文发表于ATC 2020,存储系统方向CCF-A类会议。作者是入围华为「天才少年」计划的人才之一,姚婷。
概述
现有的基于LSM-Tree的KV存储有两个缺陷:写停顿以及写放大。实验结果表明这是因为:1. L0-L1之间的compaction包含了大量数据,消耗了大量CPU资源以及SSD带宽资源;2. LSM-Tree的深度过深。
为了解决这两个问题,本文1. 设计了一种基于NVM的新型L0 SSTable格式;2. 基于该新格式提出了一种细粒度的L0-L1 compaction算法;3. 增大了每层的大小上限,从而降低了LSM-Tree的深度;4. 提出了Cross-row Hint Search用来加速在新版L0文件上的查询。
现有的LSM-Tree存在的问题
写停顿
传统LSM-Tree中的L0-L1 Compaction流程可以概括为:
- 找到最大的那个L0 SSTable t
- 找到所有与t的key-range有重叠的L0 SSTable(通常就是所有L0文件),取key-range的并集,得到input key-range r
- 找到所有与r有重叠的L1 SSTable
- 对这些SSTable进行归并排序
- 新生成的SSTable写入L1
然而,L0中每个SSTable的key-range大概率是很宽但不密的,这就导致步骤2和步骤3很可能会把L0和L1的SSTable都选中,导致一个all-to-all的全量Compaction,从而拖慢系统。
这个观点是有实验支撑的。RocksDB 中主要有三种可能的停顿:
- Too many memtable:Immutable MemTable太多了,停写等待flush完成。
- Too many level-0 SST file:L0层的SSTable太多了,停写直到L0-L1 Compaction完成减少了L0的文件数
- Too many pending compaction bytes:待Compaction的字节数太多了,停写。
通过记录不同层Flush和Compaction周期来测试这三种类型的停顿。发现L0-L1 Compaction的周期与观察到的写停顿近似匹配,如下图所示。
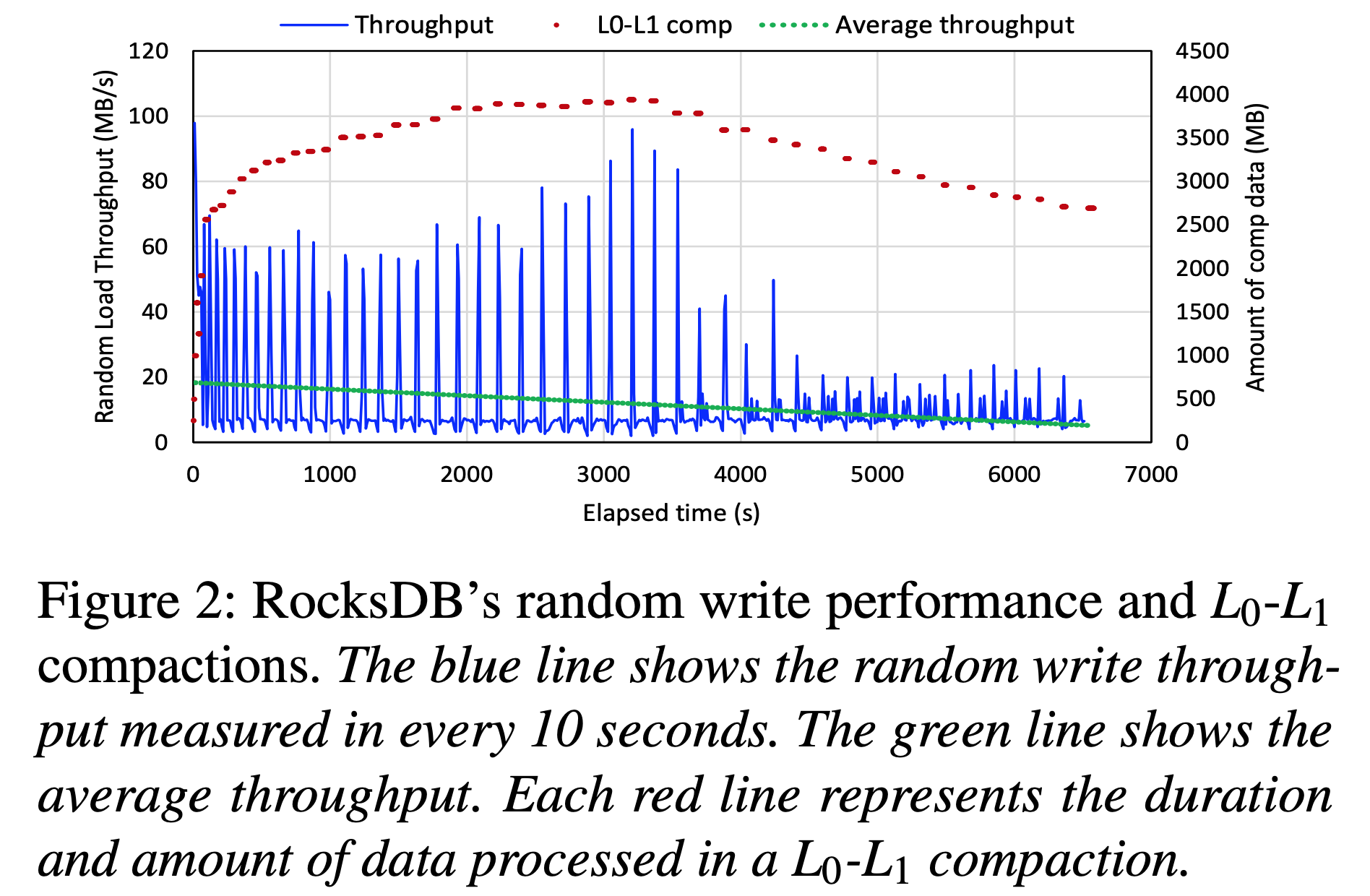
图中的每一个短红线表示一次L0-L1 Compaction,红线的长度表示持续时间,纵轴对应此次Compaction过程中处理的数量。Compaction的数据量平均大小为 3.10 GB,大量的Compaction会导致大量的读-合并-写,占用CPU周期和SSD带宽,从而阻塞前台请求,使L0-L1 Compaction成为写停顿的主要原因。
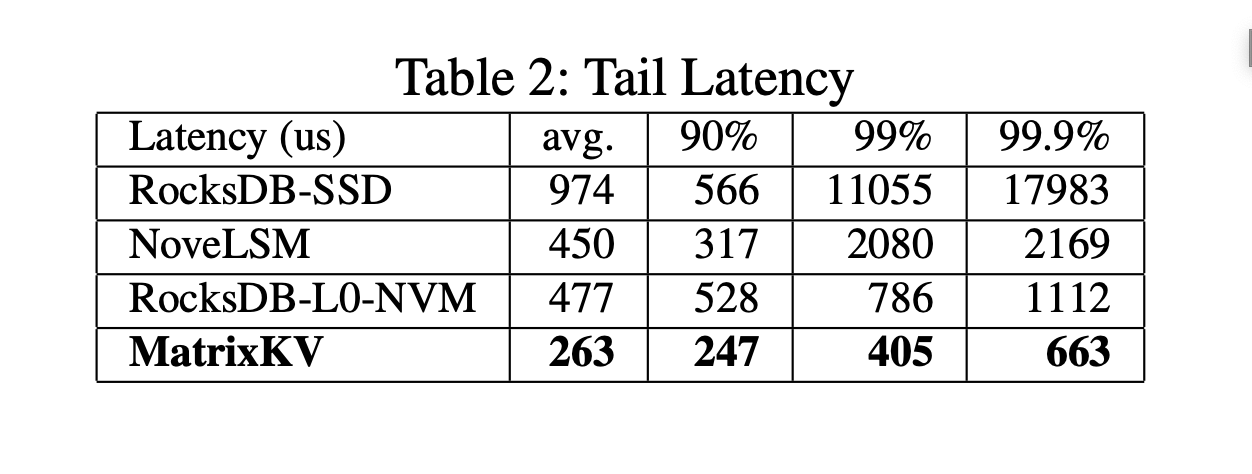
写停顿还会导致写入有长尾延迟:
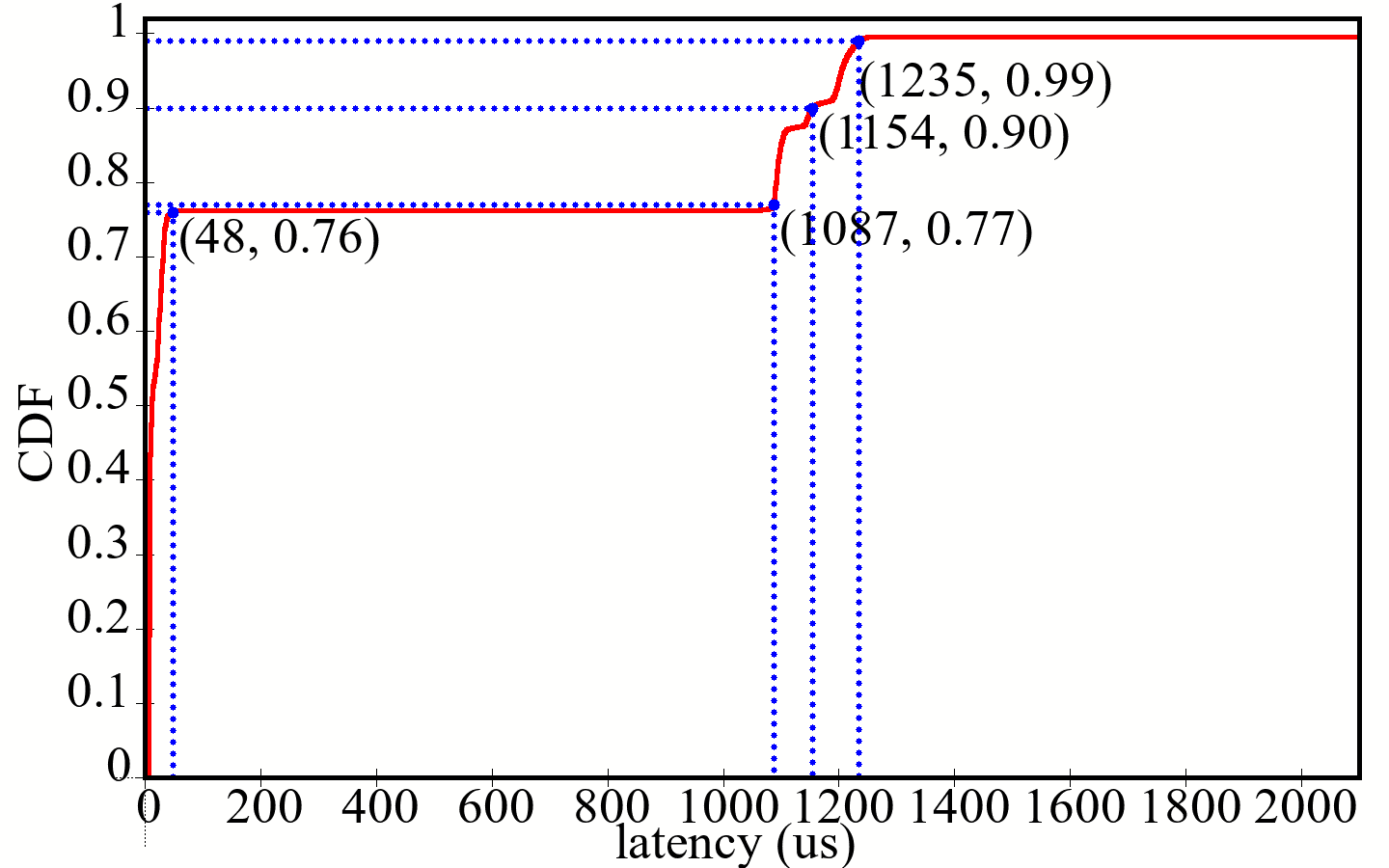
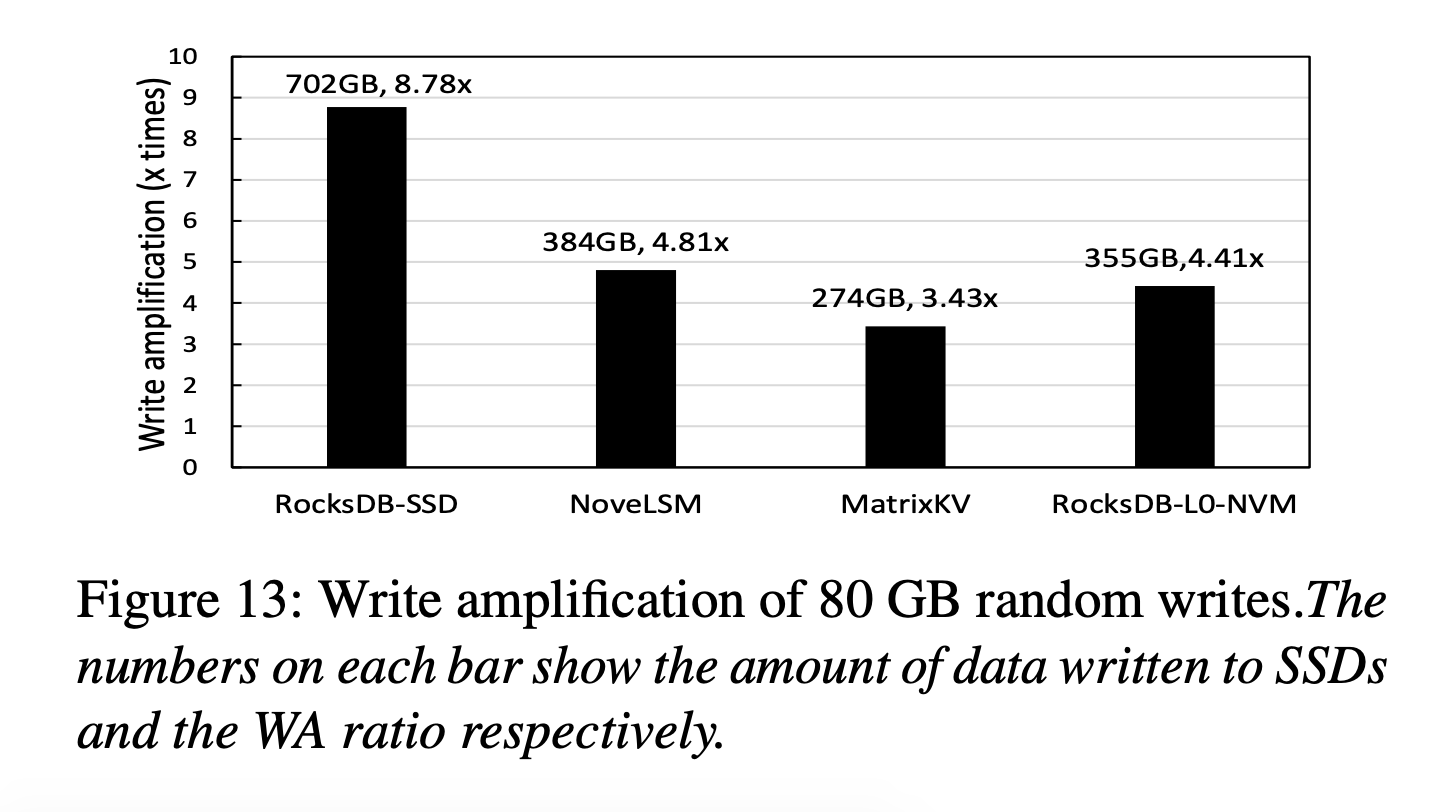
写放大
Q: 写放大怎么算
A: 比如SSTable每个2M;总共3层,每层的大小阈值比例为10(L0 2M、L1 20M、L2 200M)。那么当写完一个L0 SSTable开始Compaction时,最坏情况下和L1的10个SSTable都重叠(平均每个重叠0.2M),则需要生成10个新的L1 SSTable。由于新L1 SSTable的生成又导致了L1-L2的compaction,被选中的那个L1 SSTable同样将导致10个新L2 SSTable的生成。综合来看,为了写2M的数据,需要1个L0,10个L1,10个L2,共42M,总的写放大就是21。
默认相邻两层的大小是10倍的关系,因此总的写放大是WA=(n-1)*10+1,n是总层数。WA越大,SSD的带宽就被占的越多,最终将体现为吞吐量降低。
Q: 既然写放大是由深度过深导致的,那为什么不增大每层的大小上限呢?(保持两层之间大小比例不变的情况下)
A: L0中每个SSTable的key-range大概率是很宽但不密的。如果增大了L1的大小上限,就会导致有更多的L1 SSTable和它们有重叠,从而增大L0-L1 Compaction的压力。Q: 那如果不增大L1的上限,只增大L2及更高层的上限呢?
A: 那比例就变了,写放大也变了。
MatrixKV
Matrix Container
为了解决前面提到的L0-L1 Compaction的问题,论文先是设计了一种新的L0 SSTable格式——RowTable(位于NVM上),如下图。
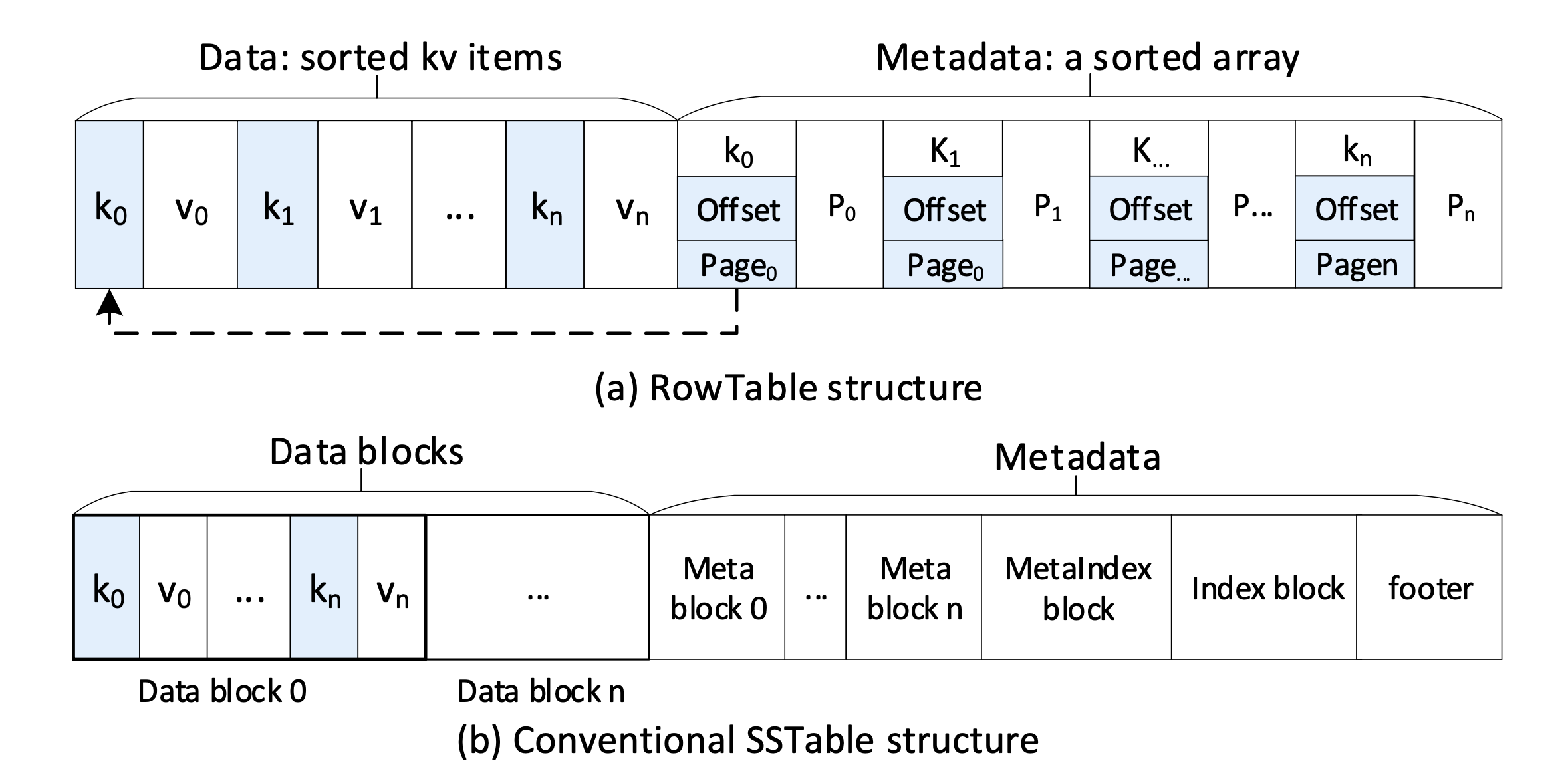
和SSTable长得很像,都分为数据区(存储kv-pair)和元数据区(存储索引信息),不同之处在于:
- 由于NVM拥有随机寻址的能力,因此不需要把数据按Block划分,也不需要IndexBlock来协助定位了,直接在元数据区做二分查找就能找到对应的page和offset。
那一层肯定不止1个RowTable,多个RowTable按新旧顺序排在一起,构成了一个Matrix Container。并且
- RowTable的元数据区还为每个key维护了一个前向指针,指向前一个RowTable的元数据区中大于等于自己的key。
于是新的L1层大概长这样
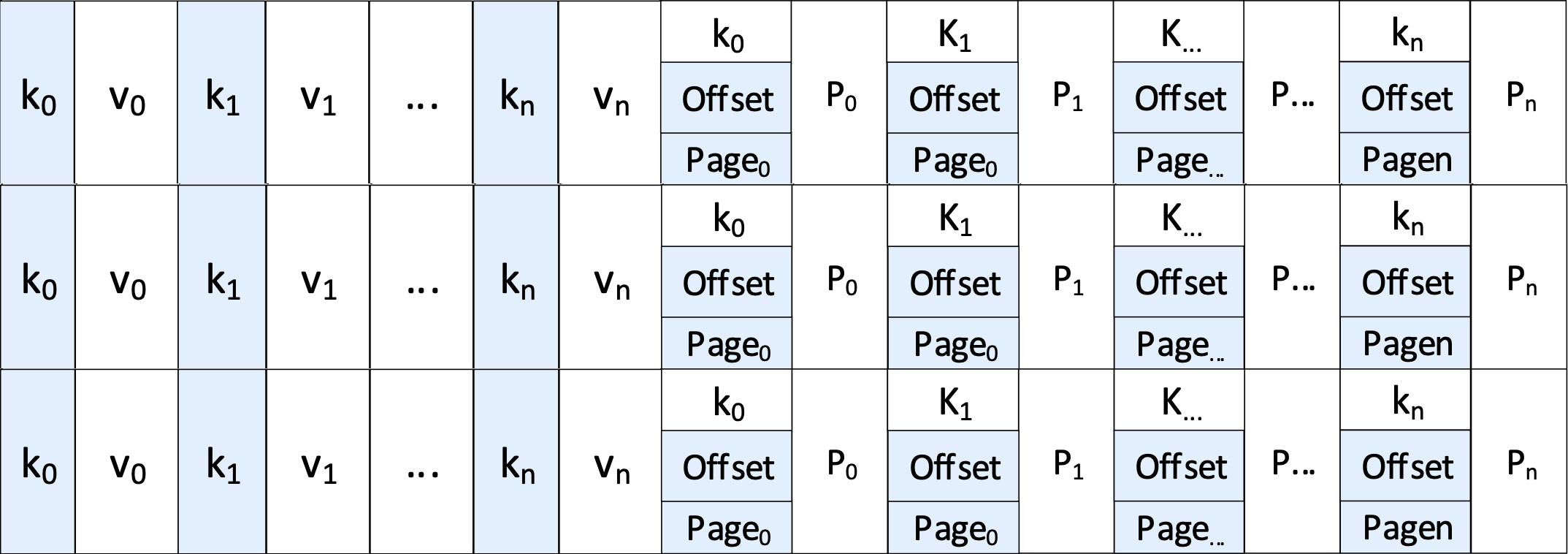
单单这个结构其实并没有什么用,构造开销和SSTable并无多大区别,也看不出有什么加速L0-L1 Compaction的效果,还需要第2个技术点来配合完成。
Q: 元数据区的必要性是什么?感觉直接把前向指针也放到数据区就好了。
A: 希望利用空间局部性?
Column Compaction
我个人觉得这个技术点起名起得不太好,Column这个词用的太广,容易引起歧义。不如叫做Progressive Compaction,即渐进式Compaction。
Column Compaction的做法是:
- 将L1的键空间划分为多个key-range。首先某个SSTable自己就提供了一个key-range,其次两个相邻的SSTable之间的缝隙也能提供一个key-range。
- 在L1中选一个起始文件,得到key-range r。
- 多线程并发的去选择落在r中的kv-pair。假设有N个RowTable,k个线程,则每个线程负责N/k个RowTable。注意这一步只是选择而已,是只读的。
- 如果数据大小没有到阈值,则加入第二个key-range。循环往复直到待compaction的数据量达到一个合适的值
- 至此所有被选中的kv-pair构成了一个逻辑上的Column。
- 对这些kv-pair以及L1中相关的SSTable在内存中合并。
- 将新的L1文件写到SSD。
- 选择下一个key-range,继续执行上述步骤。相当于形成了一个key-range环。
Q: 第6步的合并具体是怎么做的?
A:
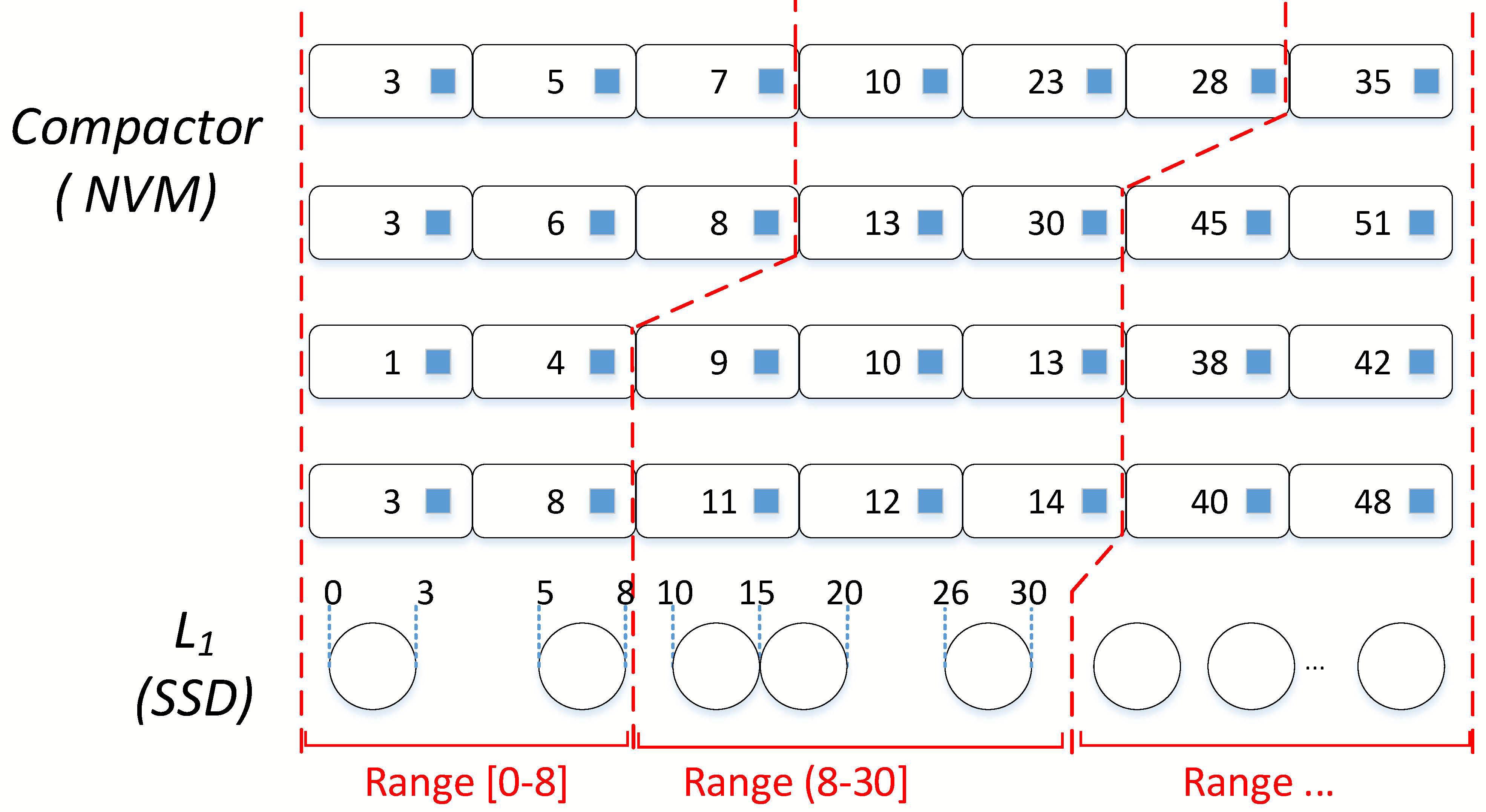
这里看个例子,一开始选中了[0, 3]这个SSTable,然后在4个RowTable的MetaData中搜索,发现pair不多,就把[3, 5]也加进来,继续搜索,还是不够,再把[5, 8]加进来,这回够了。接着就可以对2个L1 SSTable以及10个kv-pair做compaction了。下一次Column Compaction就会从[8, 10]开始。
Reducing LSM-Tree Depth
这个要改的地方很简单,调大每层的大小限制就行了。但能这么改的原因是前面把L0-L1 Compaction做成渐进式的了。
另外还有一点是改大后L0的SSTable(RowTable)变多了,会导致读请求变慢(L0不是整层有序的,读取时需要遍历)。为了不使读性能下降太多,论文提出了下面的技术点。
Cross-row Hint Search
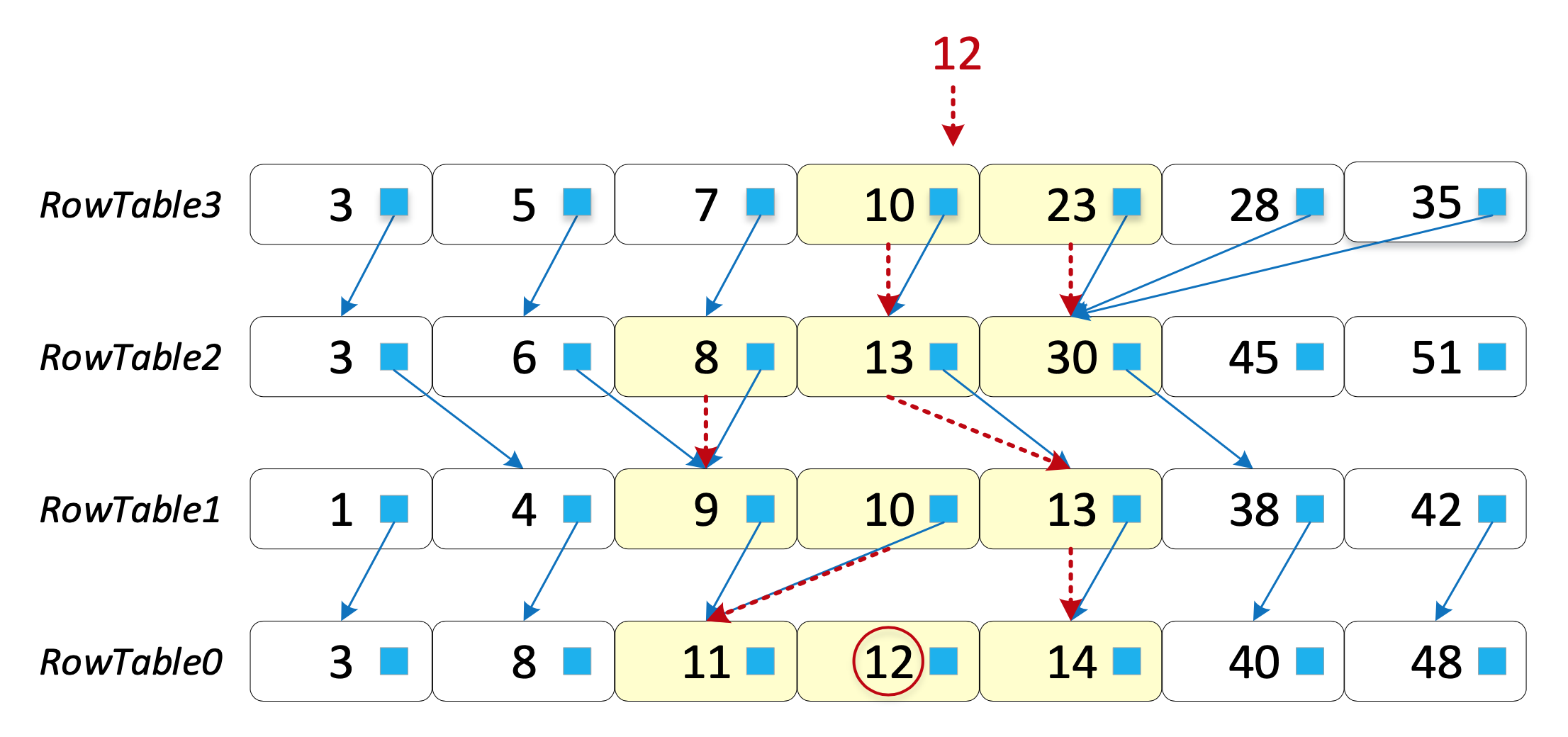
和前面说的一样,相当于一个全连接的跳表:
在元数据区为每个key维护了一个前向指针,指向前一个RowTable的元数据区中大于等于自己的key。
搜索过程比较简单,直接看例子:
比如搜索12,首先二分没找到12,但得到上下界10和23,10指向13,23指向30;由于12不在[13, 30]这个区间内,所以把前一项8加入,在[8, 30]中二分,没找到,但得到上下界8和13,8指向9,13指向13;在[9, 13]中二分,没找到,但得到上下界10和13,10指向11,13指向14;在[11, 14]中二分,找到了12。
Q: 这些技术是不是必须得在NVM上用,在SSD上能用吗?
A: 论文中并没有关于这一点的直接解释。但我的理解是在NVM中做空间释放比在磁盘中做容易得多。前向指针也更好做。
实验结果
测试环境
硬件
- 2 Genuine Intel(R) 2.20GHz 24-core processors
- 32 GB of memory
- 800 GB Intel SSDSC2BB800G7 SSD
- 256 GB NVMs of two 128 GB Intel Optane DC PMM
软件
- The kernel version is 64-bit Linux 4.13.9
- OS:Fedora 27
Baseline
- RocksDB-SSD
- RocksDB-L0-NVM(8G)
- NoveLSM 8GB NVM
- MatrixKV 8 GB L0, SSD L1 8GB
NoveLSM
设计了一种可持久化的NVM-based的MemTable,并且支持update
性能测试
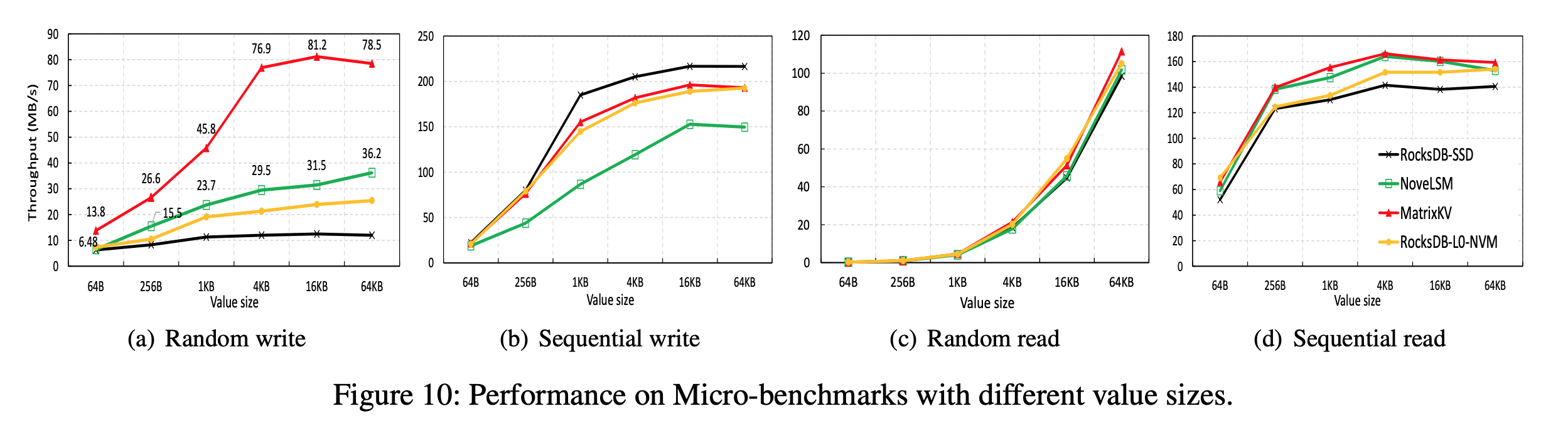
DB Bench
- 顺序写不会导致L0-L1 Compaction,所以4种方法的值都比随机写的高
- RocksDB=SSD的顺序写性能最好是因为少了一次NVM-SSD的迁移开销
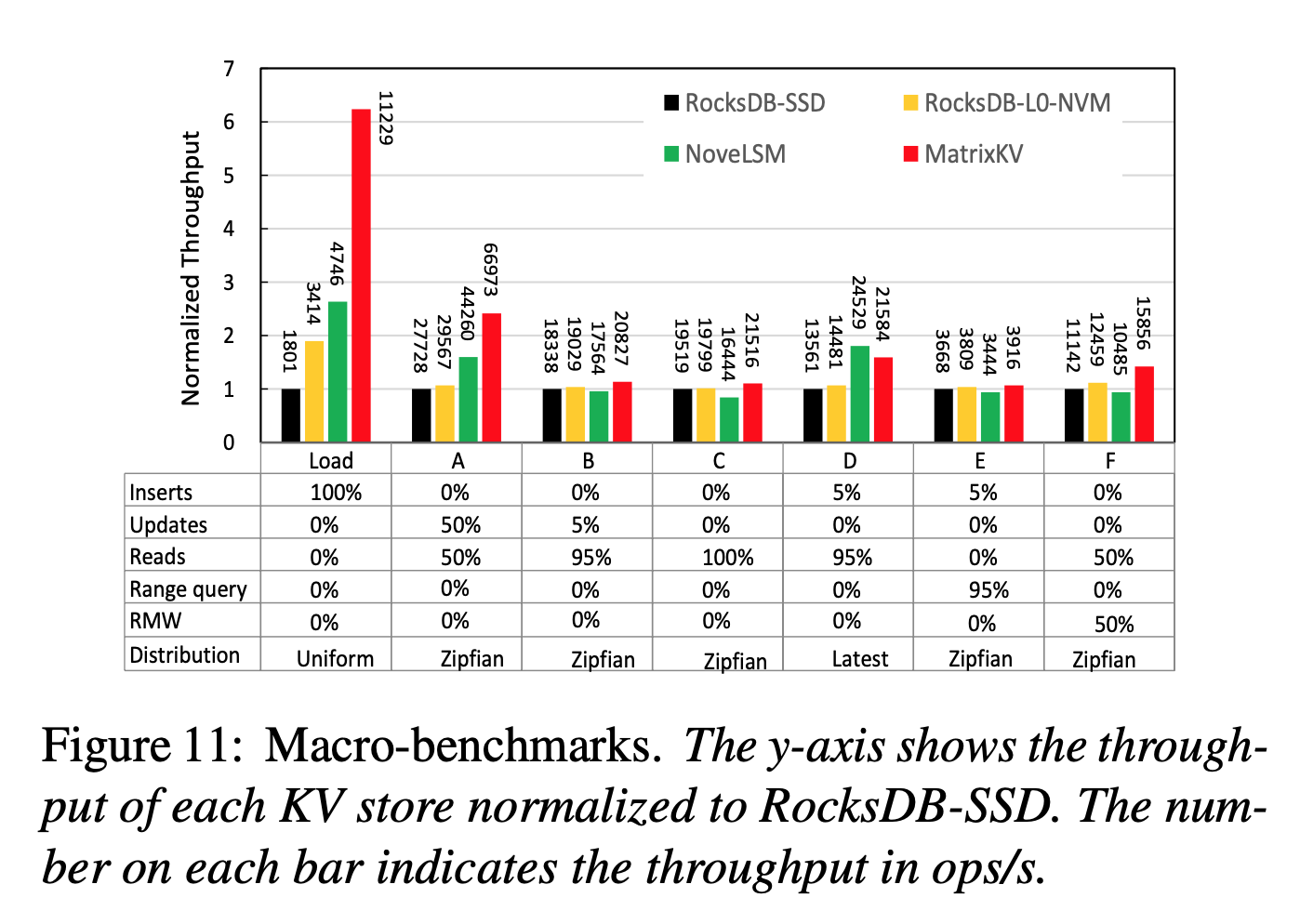
YCSB
- MatrixKV 在写密集的负载下提升效果明显
- MatrixKV 在读密集的负载下保持了平均水平
- MatrixKV 和 NoveLSM 在负载D下表现得最好是因为负载D是latest分布,使得在NVM中就能命中很多数据
写延迟显著降低
写放大系数最小
感想
技术点理解起来很容易,但idea确实很棒